N+1문제와 인덱스를 통한 조회 성능 개선
문제 상황
현재 진행 중인 스테디 프로젝트는 개발이 거의 완료되었지만 아직 API의 성능이 검증되지 않아 더미 데이터를 추가한 후 QA 및 성능 테스트를 진행하며 개선하기로 했습니다. 더미 데이터를 약 300 ~ 600 만개를 삽입 후 테스트를 하던 중 모집 글 상세 조회 API 요청 소요 시간이 2초가 넘어가는 문제를 발견했습니다.
먼저, 구조를 파악해보겠습니다.


스테디는 많은 정보를 필요로 하고 정규화가 이뤄졌기 때문에 다른 엔티티들과도 연관관계를 많이 맺게 되었습니다.

사용자들은 빠른 응답을 기대하지만 처리시간이 길어지면 사용자 경험 저하와 이탈률이 상승할 거라고 생각했습니다. 그리고 서비스 측면에서도 처리 시간이 길어지면 동시에 처리해야 하는 요청의 수가 증가하고 서버 부하의 문제로도 직결된다고 생각했습니다.
목표
성능 분석 및 벤치마킹
어느 부분에서 지연이 발생하는지 분석하고 조회를 요청했을 때 평균 응답 시간을 200ms 미만으로 줄이는 것으로 목표를 정했습니다. 이유는 모집 글 상세조회는 빈번하게 요청되는 API로 200ms 미만으로 줄인다면 사용자 경험을 향상시킬 수 있다고 생각했습니다.
원인파악 및 시도
쿼리 최적화
N+1 문제해결

스테디 상세조회에서는 Steady_Stack과 Steady_Position 과 같은 정보를 함께 반환해야 합니다. 하지만 Steady_Position, Steady_Stack과 같은 엔티티는 스테디와 일대다 관계를 맺고 있어 아래처럼 쿼리가 비정상적으로 많이 발생하는 이유의 원인이 되고 있습니다.
왜 일대다 관계가 많은 쿼리를 발생시킬까요?
예를 들어, 'Post'와 'Comment'가 일대다 관계에 있다고 가정해봅시다. 특정 'Post'를 조회할 때, 그와 연관된 모든 'Comment'들도 함께 가져오고 싶다고 합시다. 여기서 N+1 문제가 발생합니다. 첫 번째 쿼리로 특정 'Post'를 가져오는 것이 1번의 쿼리(1), 그리고 이 'Post'에 연관된 각 'Comment'를 가져오기 위해 추가적인 쿼리들을 실행하는 것이 N번의 쿼리(N)입니다. 결과적으로, 하나의 'Post'에 대해 연관된 'Comment' 수만큼 추가 쿼리가 발생하여, 데이터베이스에 과도한 부하를 주고 성능 저하를 일으킬 수 있습니다.
N + 1문제는 아래 포스팅에서 정리했으므로 여기에서는 BatchSize를 통한 해결을 선택해 적용했습니다.

인덱스 적용 고려
인덱스 적용 X


// 조회수 증가를 위해 모집글 조회 기록 조회 쿼리
explain analyze
select s1_0.id
from steady_view_logs s1_0
where s1_0.user_id=11 and s1_0.steady_id=1234567
order by s1_0.created_at desc limit 1;
4)-> Limit: 1 row(s) (cost=496452 rows=1) (actual time=9155..9155 rows=1 loops=1)
3)-> Sort: s1_0.created_at DESC, limit input to 1 row(s) per chunk (cost=496452 rows=4.83e+6) (actual time=9155..9155 rows=1 loops=1)
2)-> Filter: ((s1_0.steady_id = 1234567) and (s1_0.user_id = 11)) (cost=496452 rows=4.83e+6) (actual time=9091..9155 rows=3 loops=1)
1)-> Table scan on s1_0 (cost=496452 rows=4.83e+6) (actual time=0.101..5462 rows=5.3e+6 loops=1)explain analize 에서 분석한 내용을 확인해보면
- Table Scan on s1_0:
테이블 전체 스캔으로**483만 행**을 검색, 총 소요 시간 약 5462ms. - Filter: steady_id = 1234567 및 user_id = 11
조건에 맞는 행을 필터링, 추가 소요 시간 약 3629ms(9091 - 5462) - Sort: 필터링된 행을
created_at열 기준으로 내림차순 정렬, 추가 시간 소요 없음. - Limit: 정렬된 결과 중 최상위 1행 선택, 추가 시간 소요 없음.
즉 이 쿼리는 하나의 행을 결과로 얻기위해 480만행을 읽는 아주 비효율적인 처리로 동작했습니다.
왜 쿼리는 테이블 풀 스캔을 사용해 작업을 처리하는 것일까요?
MySQL 공식문서를 참고하면 아래와 같은 상황에 테이블 스캔이 발생한다고 안내하고 있습니다.
- 테이블이 작아서 키 조회보다 테이블 스캔이 더 빠른 경우. 이는 일반적으로 10행 미만이고 행 길이가 짧은 테이블에서 발생합니다.
ON또는WHERE절에 사용할 수 있는 인덱스가 없는 경우.- MySQL에서 인덱스된 컬럼과 상수 값을 비교할 때, 만약 해당 상수 값이 테이블의 큰 부분에 해당하고 중복도가 높다고 계산되면, MySQL은 테이블 스캔을 사용하는 것이 더 빠를 것으로 판단할 수 있음.
- 낮은 카디널리티(키 값에 해당하는 많은 행이 있는)의 키를 다른 컬럼을 통해 사용하는 경우. 이 경우 MySQL은 키 사용이 많은 키 조회를 필요로 하고 테이블 스캔이 더 빠를 것으로 가정합니다.

현재 인덱스는 PK만 등록되어 있습니다. WHERE 절에 user_id 와 steady_id를 상수 조건으로 사용하고 있지만 인덱스 컬럼이 아닌 것을 확인할 수 있습니다.
단일 인덱스
그러면 아래 명령어를 통해 각각 인덱스를 생성해 준 뒤 다시 쿼리를 실행해보겠습니다.
CREATE INDEX idx_steady_id ON steady_view_logs(steady_id);
CREATE INDEX idx_user_id ON steady_view_logs(user_id);explain analyze
select s1_0.id
from steady_view_logs s1_0
where s1_0.user_id=11 and s1_0.steady_id=1234567
order by s1_0.created_at desc limit 1;
4)-> Limit: 1 row(s) (cost=4.04 rows=1) (actual time=0.163..0.163 rows=1 loops=1)
3)-> Sort: s1_0.created_at DESC, limit input to 1 row(s) per chunk (cost=4.04 rows=4) (actual time=0.159..0.159 rows=1 loops=1)
2)-> Filter: (s1_0.user_id = 11) (cost=4.04 rows=4) (actual time=0.128..0.136 rows=3 loops=1)
1)-> Index lookup on s1_0 using idx_steady_id (steady_id=1234567) (cost=4.04 rows=4) (actual time=0.121..0.126 rows=4 loops=1)- Index Lookup on s1_0 using idx_steady_id:
steady_id=1234567에 대한 인덱스 조회로, 4행 검색에 0.126ms 소요. - Filter:
s1_0.user_id = 11조건으로 필터링, 3행 찾는데 0.126ms에서 0.136ms 소요. - Sort:
created_at열 기준으로 내림차순 정렬, 1행 정렬에 0.159ms 소요. - Limit: 정렬된 결과 중 최상위 1행 선택, 0.163ms 소요.
약 9000ms를 예측하던 분석이 단순 인덱스 추가만으로 0.163초로 줄어드는 것을 확인할 수 있었습니다.
하지만 현재는 로그에 동일한 steady_id가 4개만 존재했지만 조건에 더 많은 데이터가 존재하면 어떻게 될까요?
40만개의 데이터를 추가로 삽입한 후 똑같이 명령어를 실행했습니다.
5)-> Limit: 1 row(s) (cost=83859 rows=1) (actual time=1701..1701 rows=1 loops=1)
5)-> Sort: s1_0.created_at DESC, limit input to 1 row(s) per chunk (cost=83859 rows=163732) (actual time=1701..1701 rows=1 loops=1)
4)-> Filter: ((s1_0.steady_id = 1234567) and (s1_0.user_id = 11)) (cost=83859 rows=163732) (actual time=513..1701 rows=3 loops=1)
3)-> Intersect rows sorted by row ID (cost=83859 rows=163732) (actual time=513..1701 rows=3 loops=1)
2)-> Index range scan on s1_0 using idx_steady_id over (steady_id = 1234567) (cost=0.00195..1482 rows=759914) (actual time=0.062..511 rows=400004 loops=1)
1)-> Index range scan on s1_0 using idx_user_id over (user_id = 11) (cost=0.00195..2494 rows=1.28e+6) (actual time=0.0195..582 rows=462829 loops=1)- Index Range Scan on s1_0 using idx_user_id:
user_id = 11조건에 따른 인덱스 범위 스캔으로, 462,829행 검색에 0.0195ms에서 582ms 소요. - Index Range Scan on s1_0 using idx_steady_id:
steady_id = 1234567조건에 따른 인덱스 범위 스캔으로, 400,004행 검색에 0.062ms에서 511ms 소요. - Intersect Rows Sorted by Row ID: 두 인덱스 스캔 결과를 교차 참조하여 3행을 식별, 513ms에서 1701ms 소요.
- Filter:
steady_id와user_id조건을 만족하는 행 필터링, 추가 시간 소요 없음. - Sort and Limit:
created_at기준으로 정렬 후 상위 1행 선택, 총 1701ms 소요.
조건에 해당하는 데이터가 늘어남에 따라 쿼리가 비효율적으로 동작한 것을 알 수 있습니다. 인덱스를 적용했지만 40만 개의 데이터가 검색되었고 검색된 행을 교집합 하는 등 비용이 늘어나게 되었습니다.
처음에는 이상적으로 보이지만, 별도의 인덱스 두 개를 생성하는 방식에는 문제가 있습니다. steady_id와 user_id 각각을 빠르게 찾을 수는 있으나, 동시에 steady_id이면서 user_id인 조건을 만족하는 행을 찾는 방법은 명확하지 않습니다.
하지만 MySQL에서는 쿼리를 실행할 때 인덱스결과를 병합할 수 있는 인덱스 병합 최적화를 제공합니다. 인덱스 병합 최적화를 통해 두 개의 인덱스를 활용할 순 있지만 오버헤드가 존재합니다.
다중 열 인덱스
MySQL 공식문서에서는 다중 열 인덱스를 소개하고 있습니다.
# 인덱스 추가
CREATE INDEX idx_user_id_steady_id ON steady_view_logs (user_id, steady_id);
3)-> Limit: 1 row(s) (cost=3.3 rows=1) (actual time=0.114..0.114 rows=1 loops=1)
2)-> Sort: s1_0.created_at DESC, limit input to 1 row(s) per chunk (cost=3.3 rows=3) (actual time=0.11..0.11 rows=1 loops=1)
1)-> Index lookup on s1_0 using idx_user_id_steady_id (user_id=11, steady_id=1234567) (cost=3.3 rows=3) (actual time=0.0818..0.0868 rows=3 loops=1)- Index Lookup on s1_0 using idx_user_id_steady_id:
user_id=11및steady_id=1234567조건에 대한 인덱스 조회로, 3행 검색에 0.0818ms에서 0.0868ms 소요. - Sort:
created_at기준으로 내림차순 정렬, 상위 1행 선택에 0.11ms 소요. - Limit: 정렬된 결과 중 최상위 1행 선택, 총 0.114ms 소요.
🔍 다중 컬럼 인덱스 주의사항
테이블에 여러 열로 구성된 인덱스가 있는 경우 최적화 도구는 인덱스의 가장 왼쪽 접두사를 사용하여 행을 조회할 수 있습니다. 예를 들어 (col1, col2, col3)에 3열 인덱스가 있는 경우 (col1), (col1, col2), (col1, col2, col3)에 대한 인덱스 검색 기능이 있습니다.
MySQL cannot use the index to perform lookups if the columns do not form a leftmost prefix of the index.
즉, 지금 인덱스 추가를 user_id, steady_id 순으로 생성했고 쿼리에서 역시 인덱스와 동일한 순서로 검색을 하고 있습니다. 하지만 쿼리에서 두 컬럼의 순서를 바꾸게 되면 인덱스를 사용해 조회를 수행할 수 없다고 합니다.
하지만 직접 테스트를 해보니 속도는 느려지지만 인덱스를 활용하는것을 확인할 수 있었습니다.
explain analyze
select s1_0.id
from steady_view_logs s1_0
where s1_0.steady_id = 1234567 and s1_0.user_id = 11
order by s1_0.created_at desc
limit 1;
-> Limit: 1 row(s) (cost=3.3 rows=1) (actual time=0.0644..0.0651 rows=1 loops=1)
-> Sort: s1_0.created_at DESC, limit input to 1 row(s) per chunk (cost=3.3 rows=3) (actual time=0.0609..0.0609 rows=1 loops=1)
-> Index lookup on s1_0 using idx_user_id_steady_id (user_id=11, steady_id=1234567) (cost=3.3 rows=3) (actual time=0.0381..0.0422 rows=3 loops=1)결과
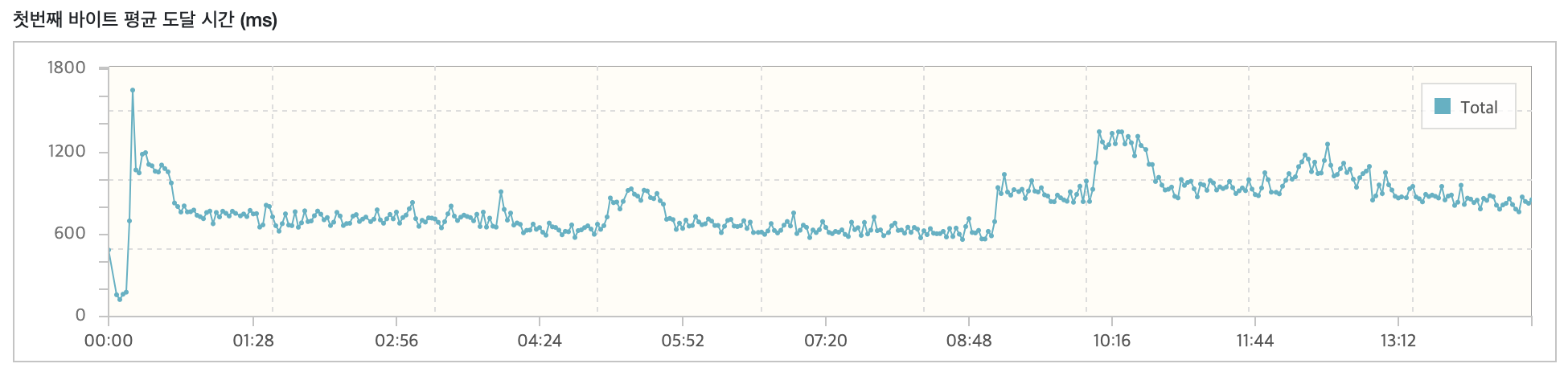
개선된 응답속도
테스트 설정은 스크립트에서 요청당 Think time을 1000ms를 설정했으며, 프로세스 2, 스레드 75를 통해 VUser를 150으로 세팅하고 Ramp-up을 사용해 10초마다 VUser를 2씩 증가시켰습니다.
서버는 AWS t2.small 인스턴스를 사용하고 Docker(MySQL8.2)를 사용해 테스트를 진행했습니다.
목표했던 단일 요청에서 응답속도를 200ms 이내로 단축시켰으며 nGrinder를 통한 성능테스트에서도 준수한 결과를 얻을 수 있었습니다.


추가로 고민할 점
모집글 상세조회 API를 성능 개선하면서 현재 API 설계의 문제점을 발견할 수 있었습니다. 현재 API는 화면 중심적인 설계로 되어있어 백엔드 코드의 복잡성이 증가하고 있습니다. 뿐만아니라 유지보수의 어려움도 느꼇습니다.
이래서 REST API를 따라야하나..? 라는 생각이 들어 API분리를 고민하고 있으며, 현재는 N+1 문제 해결과 인덱스 활용으로 성능을 개선할 수 있었지만 상세조회에 조회수의 대한 부분과 매크로 방지의 대한 부분까지 포함되어 있어 성능이 안나오는 원인이 되었습니다. 이 부분을 비동기로 분리하는 방법이나 조회 로그를 RDB에 쌓지않고 다른 방법을 통해 처리하는 방법을 고민하게 되었습니다.