
캐시 시리즈
현재 상황
병목현상
스테디 프로젝트는 메인 페이지에서 ‘좋아요’ 수 와 조회수를 기반으로 한 기간별 인기 모집 글을 보여주고 있습니다. 현재 개발 서버에는 300만 건의 데이터가 존재하고 인기 글의 기간 범위가 늘어날수록 Latency가 길어지는 문제가 발생하고 있었습니다. 인덱스를 적용했음에도 만족스러운 응답속도가 나오지 않았고 비슷한 서비스를 목푯값으로 잡아 성능을 개선해 보는 경험을 공유하려 합니다.
테스트 환경
- nGrinder , nGrinde-agent
- VUser 150 (3/50)
- Ramp-Up 사용 10s → 1 Thread 증가
- 스크립트에 ThinkTime 700ms
현재 성능
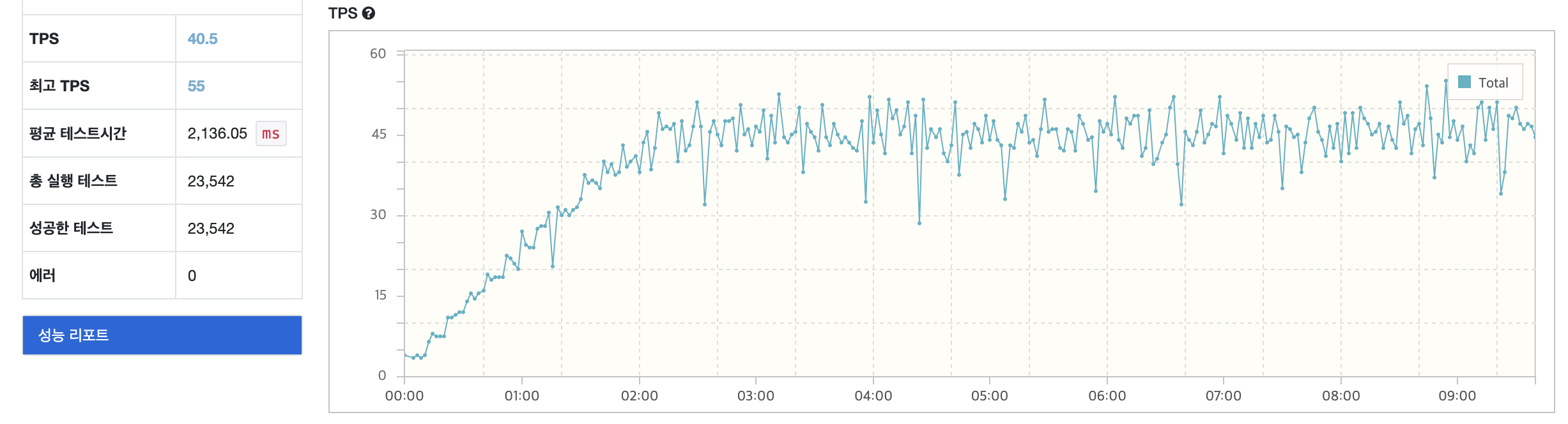

VUser 수가 약 50 부터 1초 이상의 Latency가 발생하고 있습니다. RPS가 약 40 정도로 예상되는 지점에서 병목이 발생하다는건 사용자 경험에 안좋은 영향을 충분히 줄 수 있다고 생각하고 이 부분을 개선하기 위해 캐시를 도입하기로 했습니다. 캐시를 도입한 이유는
- 모집글의 랭킹은 잘 변하지 않고 내용도 변경이 적은 데이터입니다.
- RDB를 통한 검색을 하는 시간이 오래 걸리고 매변 계산을 통해서 가져오는것은 비효율 적이라고 판단했습니다.
- 클라이언트에서 자주 호출되는 API입니다.
따라서 인기 모집 글은 캐시에 저장하기 좋은 데이터라고 판단했습니다.
목푯값
Latency & Latency in Target RPS
우선 개발자 스터디를 운영하고 있는 인프런의 정보를 활용해 목표 Time to First Byte (TTFB)와 RPS를 예상해보겠습니다.
인프런의 최대 MAU(Monthly active users)는 183만을 기록했습니다. 그리고 인프런에서 제공하는 주간인기글 API의 TTFB는 170ms로 체크했습니다.
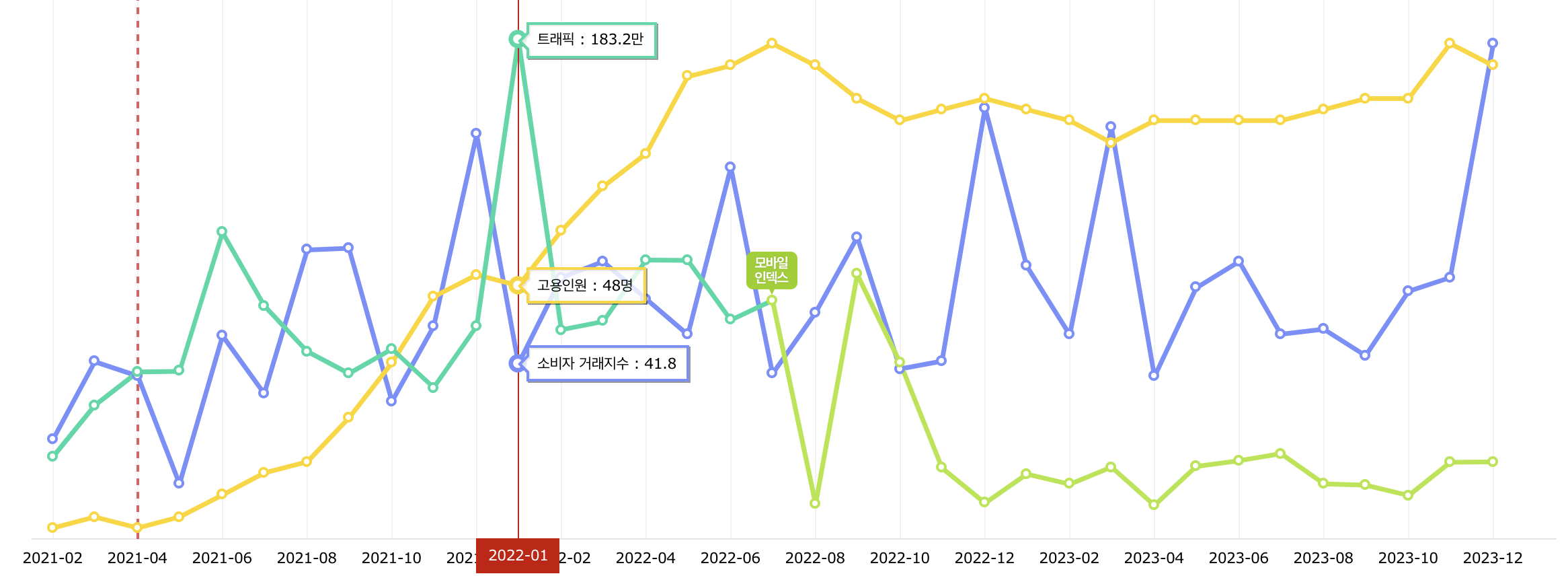

인프런 정보를 벤치마킹해 가설을 세우고 성능 테스트를 진행해 보도록 하겠습니다.
66,666 (DAU) = MAU(2,000,000) / 한 달(30일)
1일 총 요청 수(2,000,000) = 1일 사용자 수(DAU) x 1명당 1일 평균 요청 수(30회 가정)
1일 평균 RPS(46) = 1일 총 요청 수(2,000,000) / 43,200(초/12시간) → 하루 24시간이지만 서비스 특성상 낮 시간대에 요청이 대부분이라고 생각해서 12시간으로 계산
1일 총 요청 수(3,333,333) = 1일 사용자 수(DAU) x 1명당 1일 평균 요청 수(50회 가정)
1일 평균 RPS(77) = 1일 총 요청 수(2,000,000) / 43,200(초/12시간) → 하루 24시간이지만 서비스 특성상 낮 시간대에 요청이 대부분이라고 생각해서 12시간으로 계산
VUser 계산 방법
- 목표 RPS 파악: 80 RPS
- 목표 응답 시간 파악: 200ms (0.2초)
- 사용자당 요청 수 파악: 1개
VUser 수 계산
- 목표 응답 시간 200ms + 스레드 당 요청 간 시간(think time) 700ms
- 쉽게 계산하기 위해 1초에 Thread / 1s 만큼의 요청가 발생
- 따라서, 80개의 요청을 처리하기 위해서는 80 VUser 수가 필요합니다.
목표
Latency(136ms): 인프런의 TTFB(170ms) * 0.8
Latency in Target RPS(204ms): 인프런의 TTFB(170ms) * 1.2
로컬 캐시 VS 글로벌 캐시
로컬 캐시
로컬 캐시는 해당 인스턴스의 메모리 내에 데이터를 저장해 캐싱하는 전략으로 네트워크 통신 비용이 필요하지 않아 속도가 빠르고 구현이 간단합니다. 하지만 다중서버 환경에서는 데이터 일관성 유지와 확장성에 제한이 있습니다.
글로벌 캐시
글로벌 캐시는 여러 인스턴스에서 사용할 수 있는 구조로 중앙 집중화된 캐시입니다. 캐시 저장소와 통신하기 위해 네트워크 비용이 들지만 여러 서버간 데이터 동기화가 쉽다는 장점이 있습니다.
로컬 캐시를 선택한 이유
- 인기 게시물의 데이터는 크기가 작아 WAS와 메모리를 공유해도 문제없다고 판단했습니다.
- 현재 서비스는 사용자가 거의 없는 상태이며 트래픽 증가로 인스턴스가 늘어난다 해도 치명적인 일관성 문제는 없다고 판단했습니다.
- 부가적인 인프라 비용이 발생하지 않습니다. 현재 AWS의 비용을 혼자 감당하고 있어서 무시할 수 없습니다..ㅠ

캐시 라이브러리
스프링부트 공식문서에서 얘기하는 지원하는 캐시들중 몇가지만 살펴보겠습니다.
EhCache
ehCache는 메모리 뿐만아니라 디스크 저장소에 데이터를 캐싱할 수 있습니다. 중간 클러스터인 Terracotta 서버를 통해 분산 캐싱도 가능합니다.
Hazelcast
Hazelcast는 인메모리 데이터 그리드 솔루션으로 분산 캐싱, 클러스터링, 고가용성 등을 제공한다는 장점이 있습니다.
Caffeine
Caffeine은 고성능, 거의 근접한 최적의 캐싱 라이브러리로 성능 최적화가 많이 되어 있지만 분산 캐싱은 지원하지 않습니다.
카페인 캐시 적용하기
카페인 캐시는 읽기 전략에서 ehCache보다 빠른 성능을 보여주고 있는 것으로 보이고 아직 클러스터링을 고려하지 않기 때문에 Hazelcast를 제외한 카페인 캐시를 선택했습니다.

의존성 추가
// build.gradle
implementation 'org.springframework.boot:spring-boot-starter-cache'
implementation 'com.github.ben-manes.caffeine:caffeine:3.1.2'캐시 설정
@Configuration
@EnableCaching
public class CacheConfig {
private static final int ONE_DAY_SECONDS = 60 * 60 * 24;
@Getter
private enum CacheType {
STEADIES_RANK("steadies_rank", ONE_DAY_SECONDS, 15),
;
private final String cacheName;
private final int expireTime;
private final int maxSize;
CacheType(String cacheName, int expireTime, int maxSize) {
this.cacheName = cacheName;
this.expireTime = expireTime;
this.maxSize = maxSize;
}
}
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
Arrays.stream(CacheType.values()).forEach(cacheType ->
cacheManager.registerCustomCache(cacheType.getCacheName(),
Caffeine.newBuilder()
.recordStats()
.expireAfterWrite(cacheType.getExpireTime(), TimeUnit.SECONDS)
.maximumSize(cacheType.getMaxSize())
.build()
)
);
return cacheManager;
}
}캐시 적용
@Transactional(readOnly = true)
@Cacheable(value = "steadies_rank", key = "#condition.date.toString() + '_' + #condition.limit + '_' + #condition.type")
public List<SteadyRankResponse> findPopularStudies(RankCondition condition) {
List<Steady> steadies = steadyRepository.findPopularStudyInCondition(condition);
return steadies.stream()
.map(SteadyRankResponse::from)
.toList();
}결과
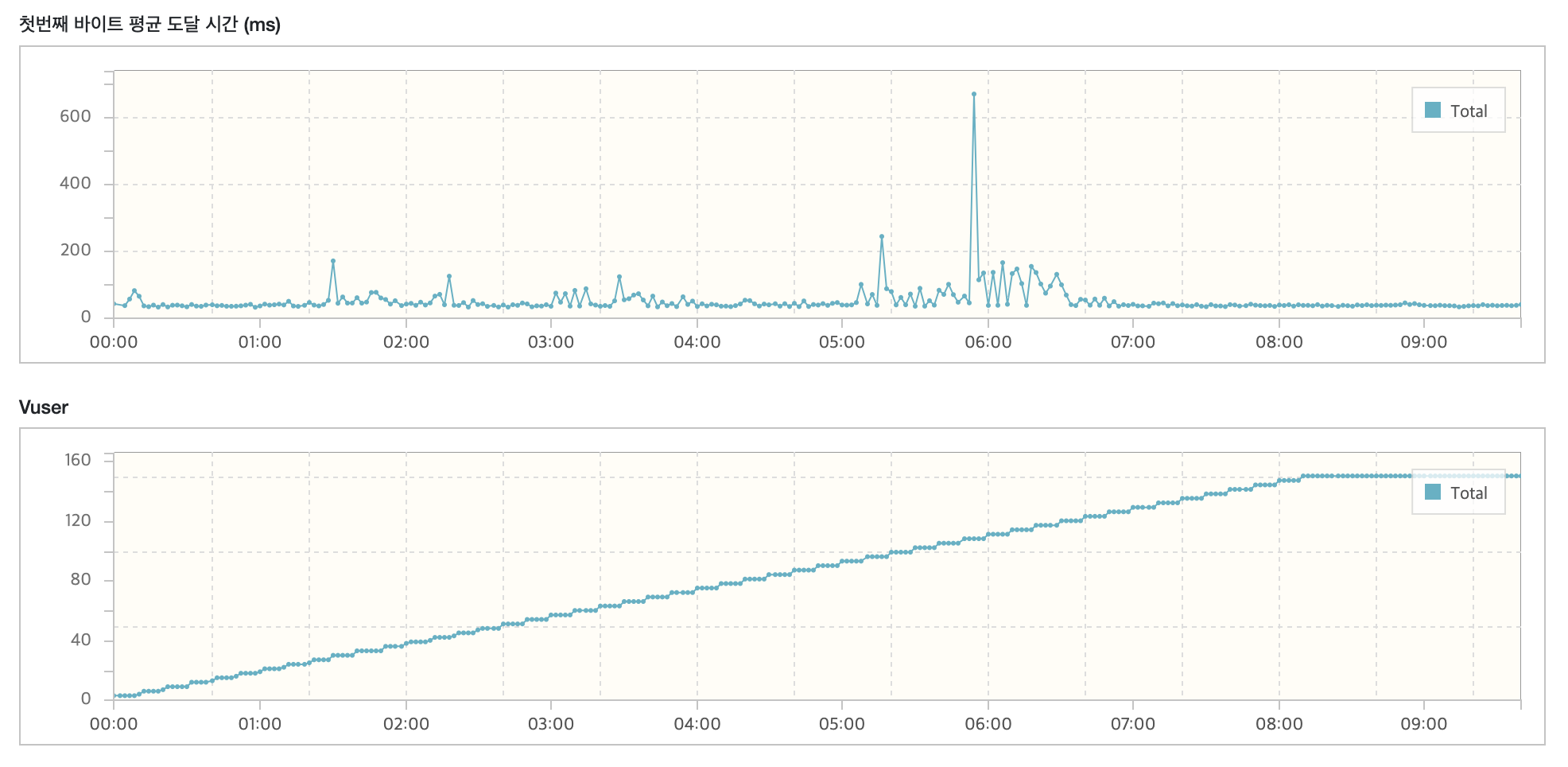
VUser가 150에 도달해도 TPS가 180 이상을 유지하며 안정적인 상태를 보여주고 있습니다. 평균 응답시간은 55ms로 엄청난 성능 개선을 보여주고 있습니다. 이로써 목표 성능을 넘어버리는 성능 개선을 경험할 수 있었습니다.
응답 속도가 1436ms에서 55ms로 개선되었고 성능은 약 2610.91% 향상되었음을 알 수 있습니다.

'BE' 카테고리의 다른 글
| 캐시를 통한 성능개선 - 이론편 (0) | 2023.12.26 |
|---|---|
| N+1문제와 인덱스를 통한 조회 성능 개선 (0) | 2023.12.12 |
| Promtail & Loki (0) | 2023.12.09 |
| 프로메테우스 & 그라파나 (0) | 2023.11.29 |
| Spring Boot Actuator & micrometer (0) | 2023.11.22 |